Enhancing AI Precision: Data Cleaning, Feature Engineering, and Labeling
Written by
Faisal Mirza, VP of Strategy
Published
August 16, 2023

Artificial intelligence (AI) has emerged as a transformative force, revolutionizing industries and driving innovation. Behind the scenes of these powerful AI systems lies a series of essential processes that ensure their accuracy, reliability, and effectiveness. In this blog post, we will explore the critical steps of data cleaning and preprocessing, the art of feature engineering, and the pivotal role of data labeling and annotation. Together, these practices form the foundation of accurate AI models, empowering organizations to make informed decisions, uncover meaningful insights, and gain a competitive edge in a rapidly evolving world.
Data Cleaning and Preprocessing: The Foundation of Accurate AI Models
In the pursuit of accurate AI models, data cleaning and preprocessing serve as fundamental building blocks. In this section, we will delve into the significance of data cleaning and preprocessing, the common challenges they address, and the techniques employed to achieve reliable data for AI training.
In the realm of AI, the quality of input data directly influences the accuracy and reliability of AI models. Data in its raw form may contain inconsistencies and imperfections that can lead to erroneous predictions and compromised decision-making. Data cleaning and preprocessing aim to transform raw data into a standardized and usable format, providing AI models with a solid and reliable foundation.
Essential Data Cleaning Techniques

Handling Missing Values
Missing data is a common challenge in datasets, and effectively addressing it is crucial for preserving data integrity. Techniques like mean/median imputation, forward/backward filling, or using predictive models can be employed to replace missing values.
Removing Duplicates
Duplicate entries can distort the analysis and lead to inflated results. Identifying and removing duplicates is a fundamental data cleaning step to ensure unbiased AI models.
Addressing Outliers
Outliers, or data points deviating significantly from the rest, can mislead AI models. Techniques like Z-score or IQR can help identify and handle outliers effectively.
Standardizing Data Formats
Data collected from different sources may be in varying formats. Standardizing the data ensures consistency and simplifies AI model development.
Transforming and Normalizing
By recognizing skewed data distributions and employing suitable transformation approaches or normalization methods, you can ensure uniform representation of data. This enhances the precision and efficiency of analysis and machine learning models.
Handling Inconsistent and Invalid Data
It’s important to identify the dataset entries that deviate from predefined standards. Set explicit criteria or validation measures to rectify these inconsistencies or remove erroneous data points.
Data cleaning and preprocessing offer numerous benefits that significantly impact AI model performance and efficiency. By improving accuracy, saving time and cost, enhancing decision-making, and increasing overall efficiency, these processes lay the groundwork for successful AI implementation.
The Basics of Feature Engineering
Feature engineering involves turning raw data into informative characteristics, enabling AI algorithms to capture complex relationships within the data. The process aims to optimize AI model predictive capabilities, leading to more accurate and robust predictions.
Key Techniques in Feature Engineering
Feature Selection
Identifying the most relevant variables that significantly contribute to the target variable is critical. Techniques like correlation analysis and feature selection algorithms help in making informed decisions about feature inclusion.
Feature Construction
Creating new features by combining or transforming existing ones provides better insights. Feature construction enhances AI model understanding and predictive capabilities.
Data Scaling
Scaling data ensures all features are on the same scale, preventing certain variables from dominating the model.
Dimensionality Reduction
Dimensionality reduction techniques like Principal Component Analysis (PCA) help compress data while preserving most of its variance, resulting in more efficient models.
Well-executed feature engineering leads to improved model performance, increased interpretability, robustness to noise, and better generalization to new data.
The Role of Data Labeling and Annotation
In certain AI applications, particularly supervised learning, data labeling and annotation play a crucial role. Data labeling is the process of manually assigning labels to the input data, providing AI models with a labeled dataset as the ground truth for training. This labeled data enables AI systems to learn from well-defined examples and generalize to new, unseen data.
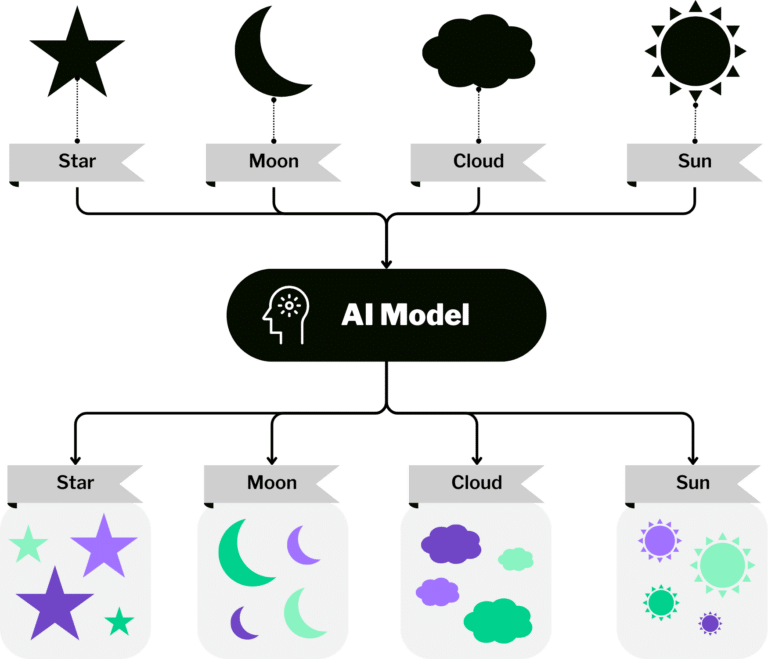
Applications of Data Labeling and Annotation
Holistic Training & Support
Image Recognition and Computer Vision
Grasping the core segments of the customer base permits banks to align their strategies with the highest growth potential sectors, optimizing the return on investment.
Natural Language Processing (NLP)
Data labeling involves tagging text data with specific labels, aiding AI models in understanding language structure and meaning.
Speech Recognition
Data labeling enables AI systems to transcribe spoken words accurately, enabling seamless voice interactions.
Accurate data labeling results in improved model accuracy, adaptability, reduced bias, and human-in-the-loop AI development.
The Roadmap to AI-Ready Data
Data cleaning and preprocessing, feature engineering, and data labeling and annotation are pivotal processes in building accurate and efficient AI models. Organizations that prioritize these practices will be well-equipped to uncover valuable insights, make data-driven decisions, and harness the full potential of AI for transformative success.
To help you navigate the complexities of preparing your data for AI, OneSix has authored a comprehensive roadmap to AI-ready data. Our goal is to empower organizations with the knowledge and strategies needed to modernize their data platforms and tools, ensuring that their data is optimized for AI applications.
Read our step-by-step guide for a deep understanding of the initiatives required to develop a modern data strategy that drives business results.
Get Started
OneSix helps companies build the strategy, technology and teams they need to unlock the power of their data.