Marketing Spend Optimization: Why AI Is the Key to Higher ROI
Written by
Jacob Zweig, Managing Director
Published
April 16, 2025

With marketing efforts spread across countless channels, each dollar spent—and each customer touchpoint—has greater impact and complexity.
Unfortunately, many brands still rely on outdated marketing models: last-click attribution, rigid budget plans, and disconnected reporting systems. These traditional approaches can’t capture the full story, leading to missed opportunities and wasted spend.
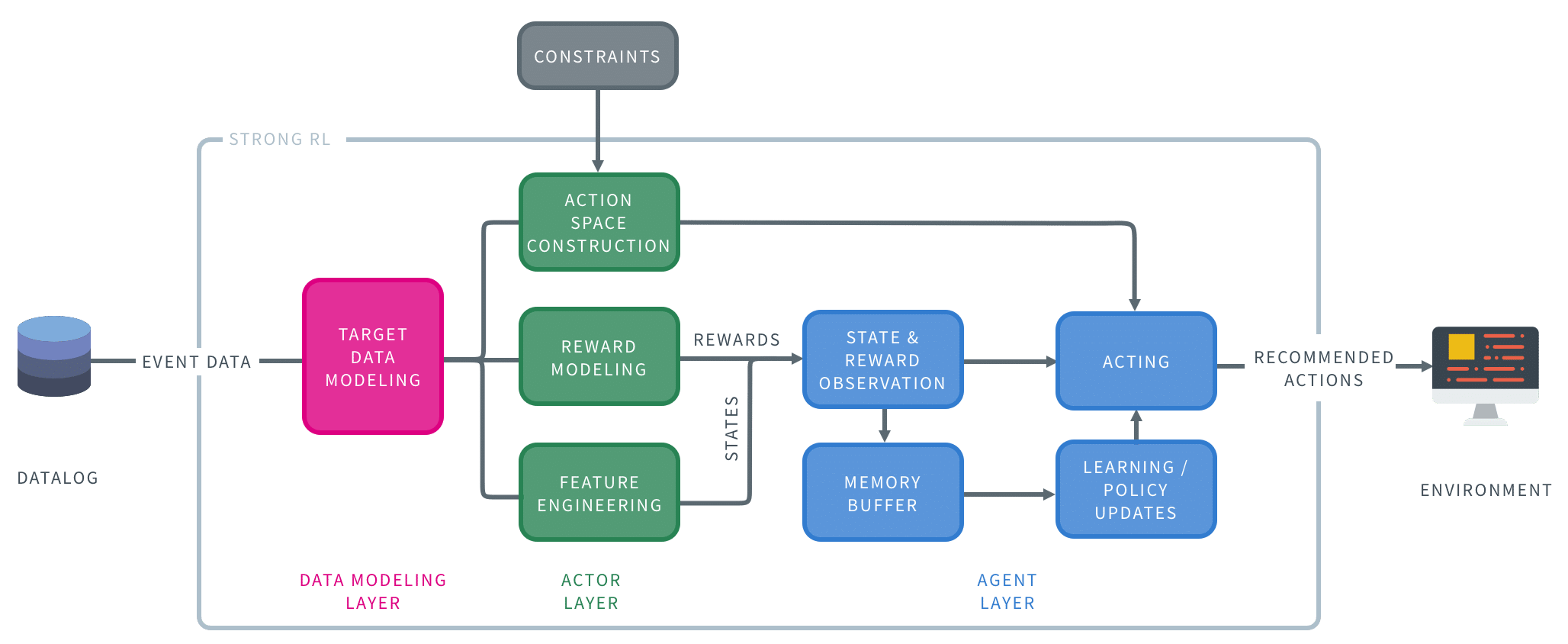
It’s time to move beyond guesswork. With the rise of AI-powered tools like Multi-Touch Attribution (MTA) and Media Mix Modeling (MMM), brands can now track the complete customer journey, attribute value across every channel, and continuously optimize their marketing strategy in real time.
In this post, we’ll explore how AI is reshaping marketing strategy—from smarter budget allocation to advanced attribution models—and how OneSix can help you turn insights into impact.
Why Traditional Marketing Strategies Fall Short
Many marketing teams still rely on legacy models—last-click attribution, manual reporting, and siloed channel analysis. These outdated methods make it nearly impossible to understand the full customer journey or justify budget allocation decisions.
In a world where customers interact with brands across multiple devices, platforms, and stages of decision-making, traditional marketing approaches simply can’t keep up.
AI-Driven Budget Allocation Optimization
AI models can analyze historical performance, campaign goals, and channel effectiveness to recommend how to allocate your marketing budget across platforms like Google Ads, social media, email, and display. Instead of relying on static budgets set months in advance, AI enables dynamic, responsive decision-making—so you’re always investing where it counts.
Multi-Touch Attribution (MTA)
See the full picture of the customer journey.
Understanding the effectiveness of your marketing efforts is no small feat—especially when customer journeys span a wide array of online and offline channels. That’s where Multi-Touch Attribution (MTA) comes in.
MTA is a powerful framework that helps marketers understand how different touchpoints—like social media ads, search campaigns, email marketing, and website visits—contribute to a customer’s decision to buy or engage. Unlike basic models that assign all the credit to the first or last interaction, MTA assigns value to multiple touchpoints across the journey, providing a more accurate, data-informed view of marketing performance.
Traditional Attribution Models: A Limited View
Before diving into advanced techniques, it’s helpful to understand where many marketers start:
- Last Touch Attribution gives all credit to the final interaction before conversion. Simple, but ignores the work done by earlier touchpoints.
- First Touch Attribution attributes 100% of the conversion to the first interaction—useful for awareness tracking, but blind to later nurturing.
- Linear Attribution spreads credit equally across all touchpoints—more balanced, but assumes every interaction is equally important.
While easy to implement, these models often produce incomplete or misleading insights, especially when trying to optimize spend across diverse marketing channels.
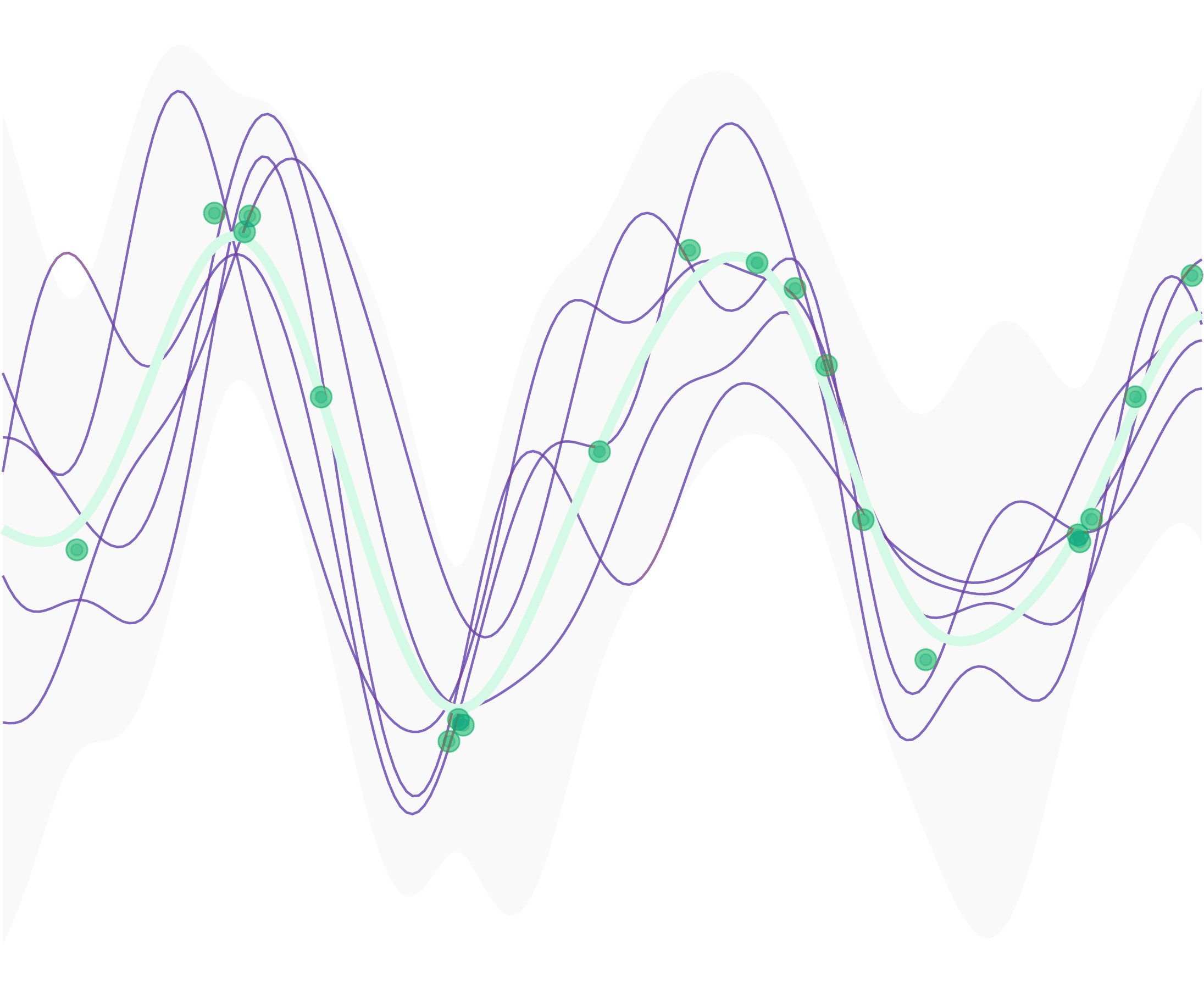
Modern MTA Models: Deep Learning for Deeper Insight
As marketing channels become more complex and customer journeys more fragmented, modern AI-driven models are filling the gap. Advanced MTA approaches—like LSTM networks, Transformers, and Temporal Convolutional Networks (TCNs)—can model sequential customer behavior, learn from historical data, and accurately assign value to each touchpoint.
LSTM-Based Attribution
Long Short-Term Memory (LSTM) networks are a type of recurrent neural network (RNN) ideal for analyzing sequences. They can process long customer journeys, understand the timing and order of interactions, and identify which touchpoints had the greatest influence on a conversion. By calculating gradients (i.e., how much a small change in one touchpoint affects the outcome), LSTM models can attribute precise credit to each step along the way.
Transformer-Based Attribution
Transformers—famous for powering models like ChatGPT—excel at understanding relationships between touchpoints, regardless of distance in the sequence. Their self-attention mechanism lets the model weigh how every touchpoint relates to every other, enabling highly nuanced attribution. This approach is ideal for complex customer journeys with many simultaneous interactions across channels.
Temporal Convolutional Networks (TCNs)
TCNs are another powerful option for modeling time-ordered data. Unlike RNNs, they use dilated convolutions to analyze sequences in parallel, which leads to faster processing and high accuracy. TCNs work especially well when journey lengths vary from customer to customer.
Applications of MTA: From Insight to Action
So how do these models translate into better business outcomes?
Smarter Budget Allocation
MTA helps marketers identify true ROI across channels and adjust budgets accordingly. For instance, if social media drives early engagement but email converts, you can confidently invest in both.
Customer Journey Optimization
MTA reveals the actual sequence of touchpoints that lead to bookings or purchases. This insight helps refine not just messaging and creative, but also the order, timing, and targeting of campaigns.
Hyper-Personalization
With granular attribution data, you can tailor marketing strategies to specific segments—delivering more relevant offers across the right channels.
From Attribution to Action: Budget Optimization in Practice
Once an MTA model is trained, it produces attribution weights that quantify each touchpoint’s influence on conversions. These weights can be used to solve a mathematical optimization problem: how to distribute your marketing budget across channels to maximize conversions or revenue.
For example, if your MTA model outputs these weights:
- Social Media Ads: 30%
- Email Campaigns: 50%
- Search Ads: 20%
You can use optimization techniques (e.g., linear programming or gradient descent) to allocate your budget in a way that maximizes return, while also considering constraints like minimum spend thresholds or strategic goals.
OneSix helps brands take these results and apply them in the real world—building automated budget optimization systems that adjust spend in real time based on performance data and predictive insights.
Media Mix Modeling (MMM)
Optimize every marketing dollar you spend.
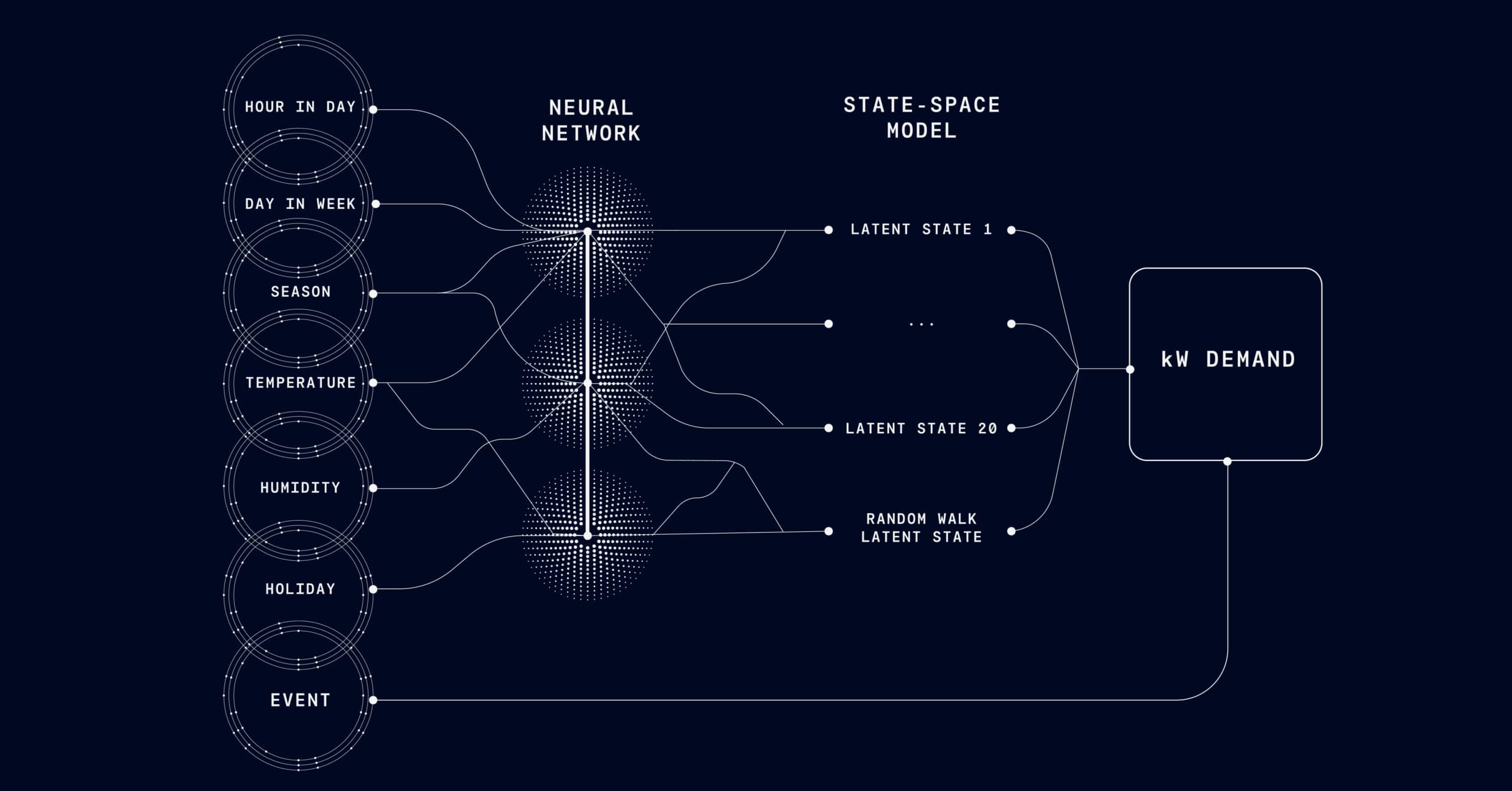
In today’s privacy-conscious environment, Media Mix Modeling (MMM) is gaining traction as a powerful, cookie-free approach to understanding marketing impact.
MMM uses aggregated historical data to quantify how different marketing activities—like TV, paid search, influencer campaigns, or email—affect outcomes like revenue, conversions, or customer lifetime value. It’s especially valuable when dealing with long buying cycles, offline conversions, or regional campaign variations.
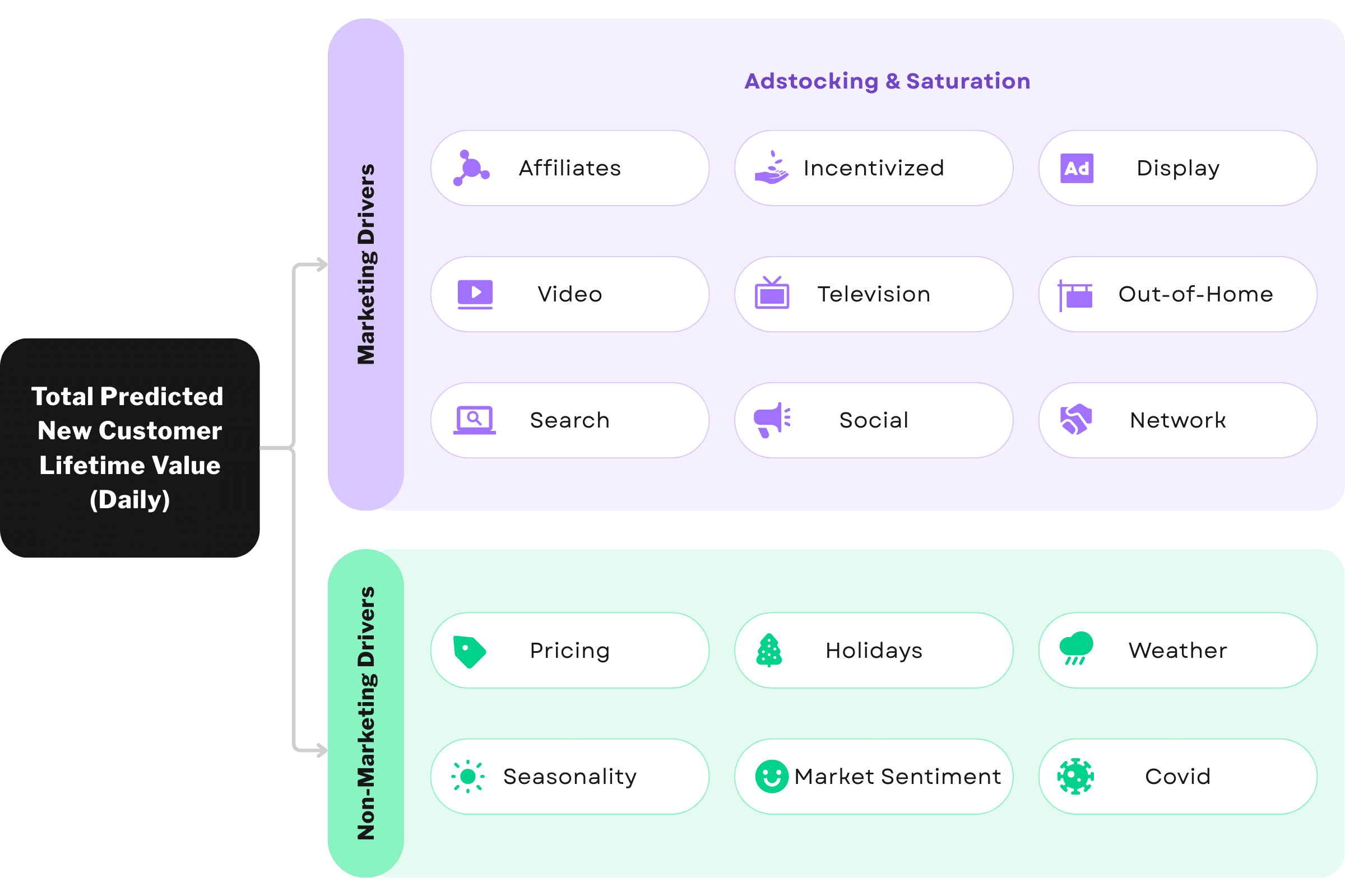
Why Brands Are Turning to MMM
As marketing strategies grow more complex, so does the challenge of proving ROI. MMM addresses this by offering:
Improved ROI Visibility
MMM pinpoints which marketing efforts actually drive results, helping you spend smarter across channels.
Increased Accountability
With clear metrics on effectiveness, you can confidently justify your budget decisions to leadership.
Real-Time Optimization
With modern tooling and infrastructure, MMM isn’t just a once-a-year exercise—it can be run regularly to adapt to market changes.
Multi-Touch Influence
MMM can capture the cumulative impact of various touchpoints—even those traditionally difficult to measure, like print media or influencer impressions.
Privacy Resilience
Unlike methods that rely on user-level tracking or cookies, MMM uses aggregate data, making it a future-proof strategy in a privacy-first world.
Reduced Bias in Decision-Making
Advanced MMM models automate decisions around ad fatigue, seasonality, and spend thresholds, removing guesswork and gut-feeling from critical marketing calls.
How MMM Works: The Mechanics Behind the Model
MMM builds a statistical model that connects marketing activities and external factors to your key business outcomes. Here are two of the most important concepts:
Adstocking
Not all marketing effects are instant. Adstocking accounts for the delayed impact of a campaign—for example, the lingering effect of a billboard or a TV commercial. This allows the model to recognize how impressions continue to influence behavior days or weeks after the initial exposure.

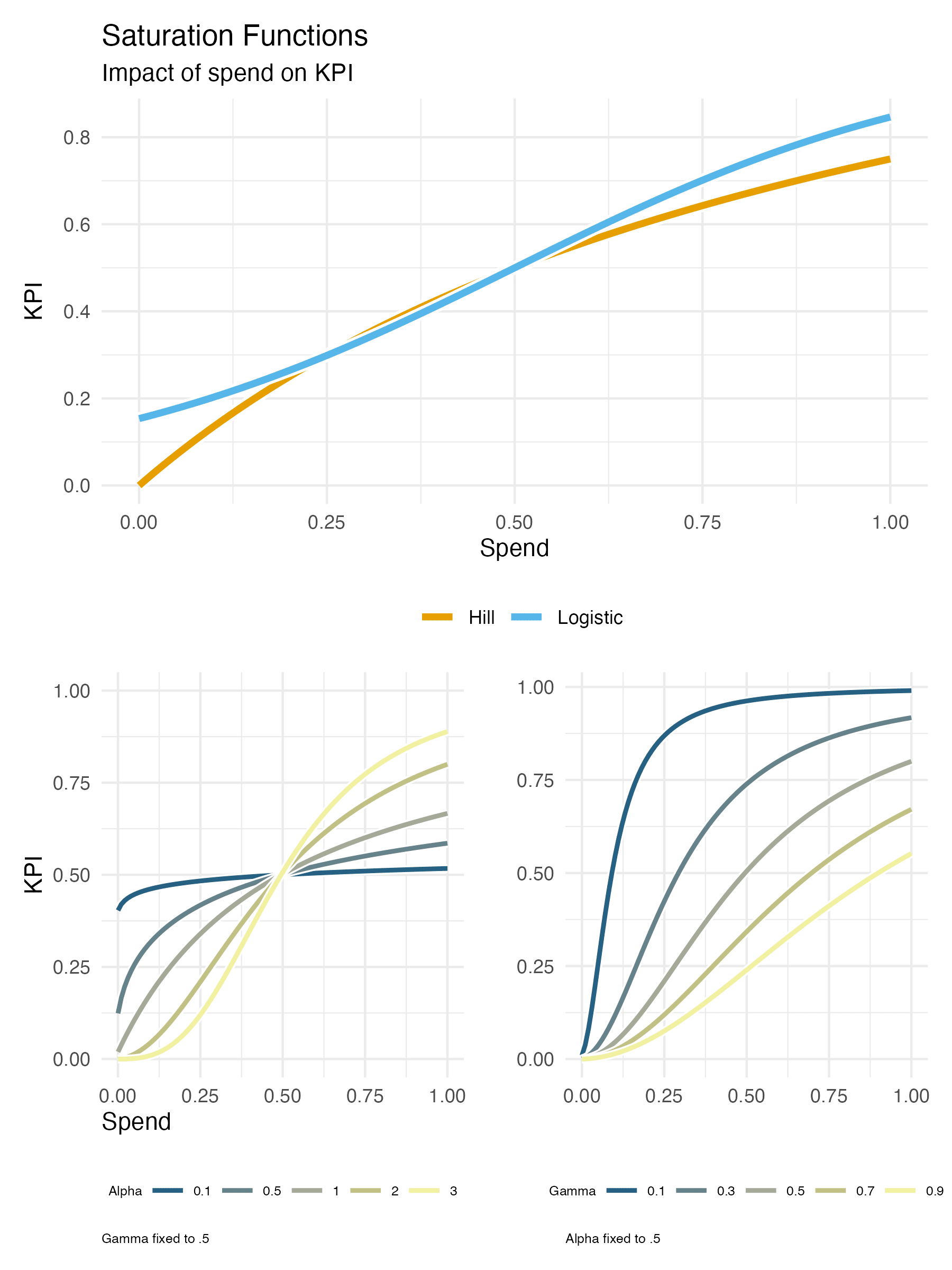
Saturation
Every channel has a point of diminishing returns. MMM models use saturation curves (often modeled with a Hill function) to understand when added spend in a channel stops yielding proportional returns. This is crucial when planning budgets across multiple media types with vastly different spend efficiency curves.
MMM also adjusts for external factors like pricing, market conditions, and seasonality—ensuring you isolate marketing’s true impact.
Off-the-Shelf vs. Bespoke MMM: Choosing the Right Fit
There are a number of tools available to implement MMM—each with its strengths and trade-offs.
Off-the-Shelf Tools
- Facebook’s Robyn: A robust, open-source MMM solution that uses ridge regression and genetic optimization. Robyn is great for quick time-to-value and offers excellent visual reporting, but it lacks a probabilistic framework and requires manual model selection—leaving room for bias.
- Google’s LightweightMMM: A probabilistic (Bayesian) alternative that provides uncertainty estimates and supports geographic modeling. LightweightMMM is better for teams wanting more transparency and statistical rigor, though it requires additional effort to build custom reporting dashboards and isn’t officially supported by Google.
Custom/Bespoke MMM Solutions
For brands with unique needs—such as regional campaign structures, legacy data systems, or complex business rules—a custom MMM model may be the best route. These models offer:
- Full control over how media effects are modeled
- Easy integration into your existing data warehouse or BI tools
- Flexibility to match your exact business and campaign requirements
OneSix partners with clients to design and implement bespoke MMM solutions, from initial data exploration through production-ready deployment—ensuring that the model aligns tightly with your business goals and marketing operations.
From Modeling to Optimization: Turning Insights into Action
Once an MMM model is built, it generates a set of channel-level performance metrics—like marginal ROI and efficiency curves. These metrics feed directly into budget optimization models, helping you decide how much to spend on each channel to maximize ROI, given your total budget and business constraints.
Example:
- Email: 3x ROI (diminishing after $10k/month)
- Paid Search: 2.5x ROI (diminishing after $25k/month)
- Influencer Partnerships: 1.8x ROI (but with long adstock)
Using these inputs, OneSix can help you solve for the optimal budget allocation using methods like linear programming or Bayesian optimization—automating the process of getting the most out of your spend.
Move Beyond Guesswork. Start Optimizing with AI.
Modern marketing requires more than clever creative—it demands clarity, precision, and adaptability. AI-powered solutions like MTA and MMM help brands cut through complexity and optimize every dollar. At OneSix, we build advanced marketing analytics frameworks that drive visibility, efficiency, and smarter decisions. Ready to make your marketing work smarter? Let’s talk about how to elevate your strategy and optimize your spend.
Contact Us