Data Engineering: The Backbone of Snowflake Data Cloud
Written by
Kwon Lee, Senior Manager
Published
May 7, 2024

Snowflake functionality can be overwhelming. And when you factor in technology partners, marketplace apps, and APIs, the possibilities become seemingly endless. As an experienced Snowflake partner, we understand that customers need help sifting through the possibilities to identify the functionality that will bring them the most value.
Designed to help you digest all that’s possible, our Snowflake Panorama series shines a light on core areas that will ultimately give you a big picture understanding of how Snowflake can help you access and enrich valuable data across the enterprise for innovation and competitive advantage.
Foundational to Snowflake is its ability to easily collect, store, and transform your data for different analytics workloads. This is Data Engineering and often will function as the backbone of all that’s possible. We’ve highlighted a few key data engineering features to help paint the picture of what you can do with Snowflake.
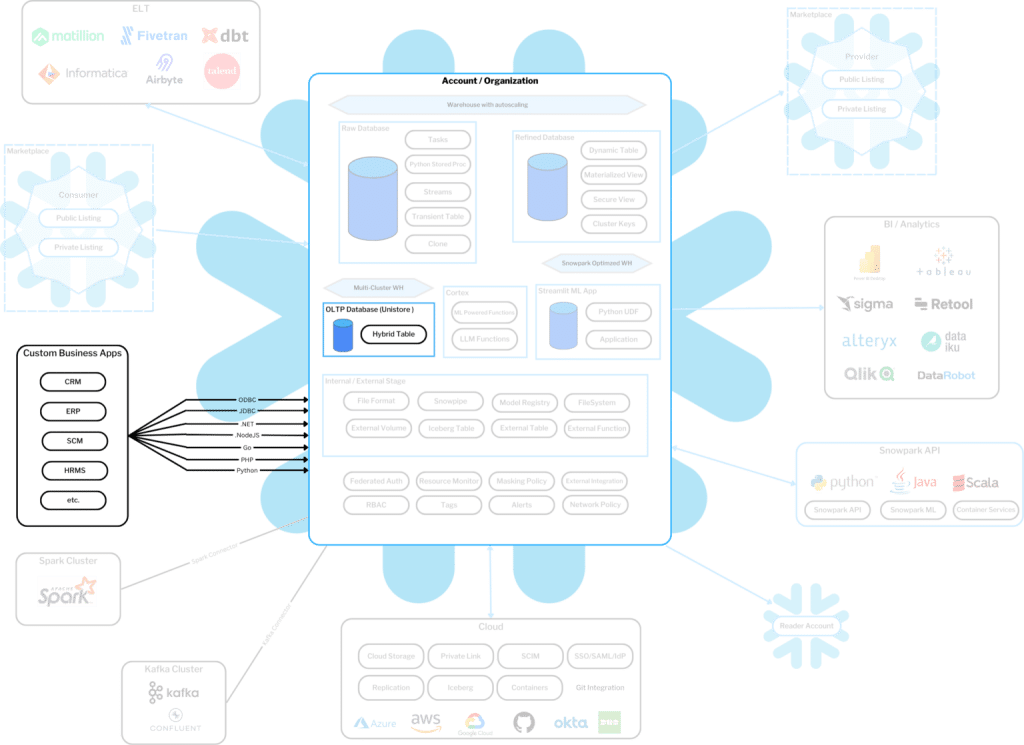
Collect/Store
Snowflake Marketplace
Centralizing data from applications and systems customers use internally is table stakes for any organization. What Snowflake augments to this process is the ability for organizations to easily discover and access datasets and services relevant to their business in the Snowflake Marketplace. For example, our client in the energy industry has retired complex, legacy data pipelines by leveraging marketplace-offered databases for key pricing data. This enables them to access real-time prices at their fingertips without the cost and time commitment to building and maintaining workloads internally.
Kafka Connector
Data from applications can often be challenging to store and analyze because of its semi-structured formats like JSON. And streaming data like this to an analytics environment used to be a heavy lift for an organization. The Confluent Kafka Connector from Snowflake makes this process seamless. A client who leverages AWS MSK for their core application (which includes events and transcripts from their core application) streams them to Snowflake in a native format that allows for parsing and analysis by the engineering and data science team. Changes to the schema in Kafka do not disrupt the ingestion into Snowflake.
Snowpipe
A clear benefit of the cloud-native world we live in today is the low cost of storage. Organizations have leveraged this to land data from internal and external systems to AWS S3, Azure ADLS, or Google Cloud Storage. However, analyzing the data while in storage is not always straightforward or easy. Snowpipes offer a real-time ingestion capability to copy data in storage to the Snowflake Data Cloud. One healthcare organization that owns a portfolio of companies with different EMRs lands exported data files into a central Azure container where Snowpipes are set up to automate the file ingestion into Snowflake for merging and analyzing the data downstream.
Iceberg Tables
There are, however, times when copying data into Snowflake’s managed storage is not the best choice for an organization’s analytics use cases. Whether it is because the data is of a much large-scale, the data needs to be in your own storage for regulatory reasons, and/or the data needs to sit in an open source format for other internal processes/applications, Snowflake also has the capability to run workloads directly on your storage via Iceberg tables, making Snowflake’s core features available even when data cannot move beyond your managed cloud storage.
Transform
Partner Ecosystem for Data Transformations
Regardless of what data is collected and stored, data transformations remain a core activity to make raw data valuable for insights and innovation. Snowflake offers a rich partner ecosystem that provides customers a spectrum of toolsets to cleanse and augment data for meaningful interpretation. Tools like Matillion Data Productivity Cloud offers a visual, self-documenting path towards creating orchestration and transformation pipelines, whereas dbt provides an open source or managed environment for building data models with a full-code experience.
Snowflake Native Features
If a customer chooses to stay within the Snowflake Data Cloud itself for data transformation, there are features like Stored Procedures, UDFs (user-defined functions that can be written in Python, Java, Scala, etc.) and Tasks that you can leverage to build your own orchestrations and workflows to build a dataset that provides value.
Ready to unlock the full potential of data and AI?
Book a free consultation to learn how OneSix can help drive meaningful business outcomes.