Iceberg Tables: The Future of Data Architecture
Written by
Ryan Lewis, Sr. Manager
Published
October 30, 2024

TL;DR
Open table formats like Iceberg are the future of data architecture because they provide for enhanced governance and interoperability across various data platforms. Data platform leaders like Snowflake are rapidly adding features to leverage the power of Iceberg.
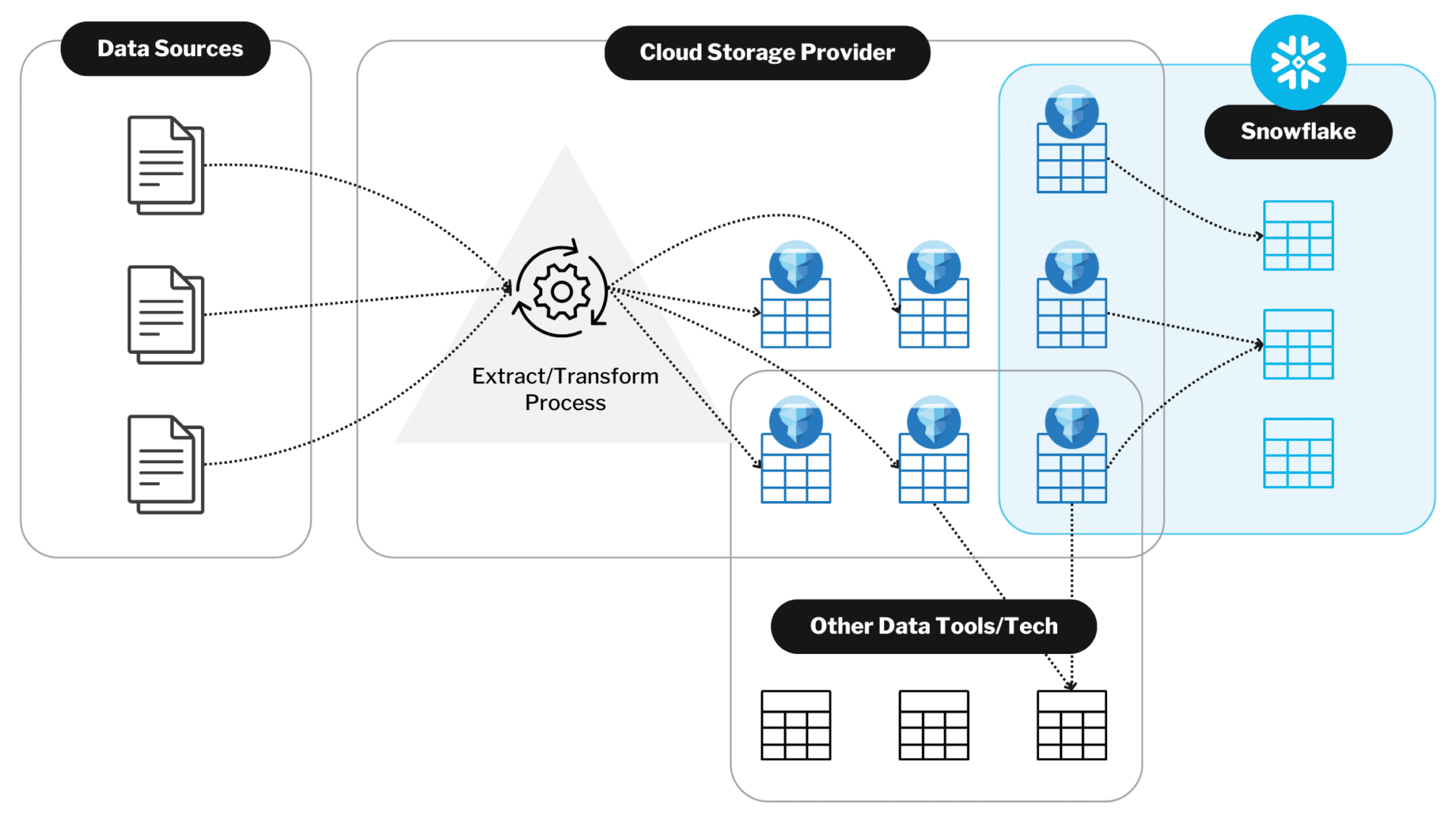
In data engineering, we ETL: Extract, Transform, Load (we still call it that, although nowadays we mostly ELT). Now ask, which of the three is most valuable? Business value is realized in the transformation process. Pulling data out of and pushing it into databases is a necessary evil that engineers spend countless hours performing. The beauty of Iceberg tables is to be able to do all of your extraction, loading, and even some transformations in one platform-agnostic location, and then access that data using any tool that you want.
What Are Iceberg Tables?
Apache Iceberg is an open table format that enables organizations to manage and query large-scale datasets stored in distributed file systems like Amazon S3, Azure Data Lake Storage (ADLS), and Google Cloud Storage (GCS) while retaining the structure and flexibility of traditional databases. By supporting SQL-like queries, schema evolution, and ACID compliance, Iceberg tables allow data teams to work efficiently at scale. Iceberg isn’t the only open table format, but it does seem to be gaining the greatest adoption and momentum of the various options.
For platforms like Snowflake, Iceberg enables seamless querying of external data without the need to import it into Snowflake. This approach provides organizations with greater flexibility and control over their data, while also optimizing cost and performance.
Why Should You Use Iceberg Tables?
Apache Iceberg prioritizes flexibility by enabling data stored in object stores to be accessed by multiple compute engines like Snowflake, giving companies freedom to choose the best tool for each task. Its nature as an open format prevents the looming risk of vendor lock-in, allowing seamless platform transitions while preserving data integrity. For years, data architects have rightfully championed the need for single sources of truth, and Iceberg tables offer strengthened governance by managing data models outside of the various data platforms, creating a truly open, agnostic, and centralized data repository.
When Should You Avoid Iceberg Tables?
While Iceberg presents its advantages, it’s not a universal solution. Compatibility, for one, remains a hurdle: the current ecosystem of data platforms and BI tools hasn’t universally embraced Iceberg, making it essential for organizations to confirm that their analytics stack can support it seamlessly. Complexity is another factor. For smaller teams or those with straightforward data demands, the sophistication of Iceberg can introduce unnecessary layers of management. In these cases, a traditional databases might better serve their needs, offering efficiency without the overhead.
Who Benefits Most from Iceberg Tables?
Large enterprises with complex data ecosystems and multiple analysis tools are prime candidates for Iceberg. The ability to manage and query data across different platforms without duplicating it provides substantial value, especially during mergers and acquisitions. In these scenarios, consolidating data platforms from multiple companies can be challenging and costly. Iceberg simplifies this process by creating a unified data architecture, allowing organizations to integrate diverse data sources seamlessly without extensive data migration or replication.
Smaller companies or data teams can also benefit from Iceberg, depending on their requirements. If they anticipate growth or need flexibility in their analytics capabilities, adopting Iceberg early on could be advantageous, as it allows them to scale efficiently and avoid vendor lock-in as their needs evolve.
Why the Shift Towards Iceberg?
The data architecture landscape is shifting as enterprises realize the costs associated with vendor lock-in and data duplication. Iceberg offers a solution that supports a unified data architecture—where data remains in a single location while being accessible across various platforms. This minimizes governance challenges and provides a single source of truth.
Major Data Platforms and Iceberg Adoption
Snowflake
Snowflake has been expanding its support for Iceberg, particularly for managing external tables. This development allows organizations to query external data directly, offering a flexible and cost-effective option for integrating with other cloud platforms.
AWS
Iceberg on Amazon S3 integrates with AWS Glue Data Catalogs, supporting multiple OTFs, including Hudi and Delta Lake, making it a versatile choice for data management in AWS ecosystems.
Google Cloud
Recently, Google announced BigQuery tables for Iceberg, further evidence that Iceberg is becoming central to modern data architectures.
Microsoft Azure
Currently, Azure’s ecosystem remains more focused on Delta Lake. However, the growing demand for Iceberg may prompt future support developments.
Key Considerations for Implementing Iceberg Tables
Performance
Querying native tables has better query performance than Iceberg tables. If performance is a major consideration, you may consider creating pipelines to move some of your external Iceberg tables into your data platform. This negates the benefits of using Iceberg, so it’s important to understand your performance needs.
Cost Efficiency
Storage is inexpensive, and with Iceberg, you pay only for data storage and the compute engine used for querying and transformation. Significant savings are likely if you’re currently building redundant pipelines across platforms or frequently exporting and importing data between multiple tools, beyond the typical data extraction.
AI and Machine Learning Initiatives
Iceberg’s ability to create a consistent and flexible data source across platforms simplifies the development of AI pipelines. It reduces the need for complex ETL pipelines and minimizes data duplication, accelerating AI and ML initiatives.
Is Iceberg Right for Your Organization?
Iceberg tables are shaping the future of data architecture, providing the flexibility, compatibility, and performance that modern enterprises need. As more platforms support Iceberg, it will likely become the standard for data lakes and warehouses, allowing organizations to break free from vendor lock-in and maintain a unified data strategy.
Get started with Iceberg tables
Book an consultation or chat with us in-person at Snowflake World Tour Chicago on November 4th.
Contact Us